CREATE TABLE orderinfo (
orderno INTEGER AUTO_INCREMENT PRIMARY KEY,
user VARCHAR(20),
isbn VARCHAR(20),
quantity INTEGER,
date date
)ENGINE=InnoDB;
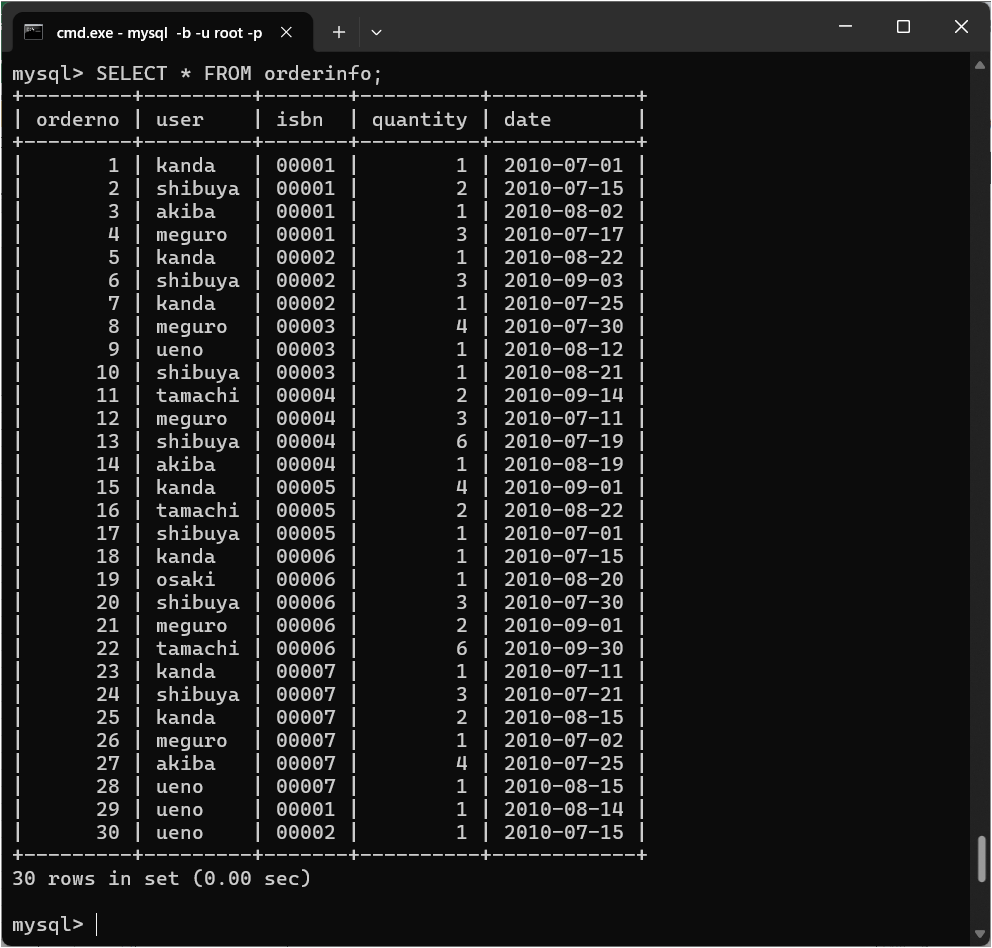
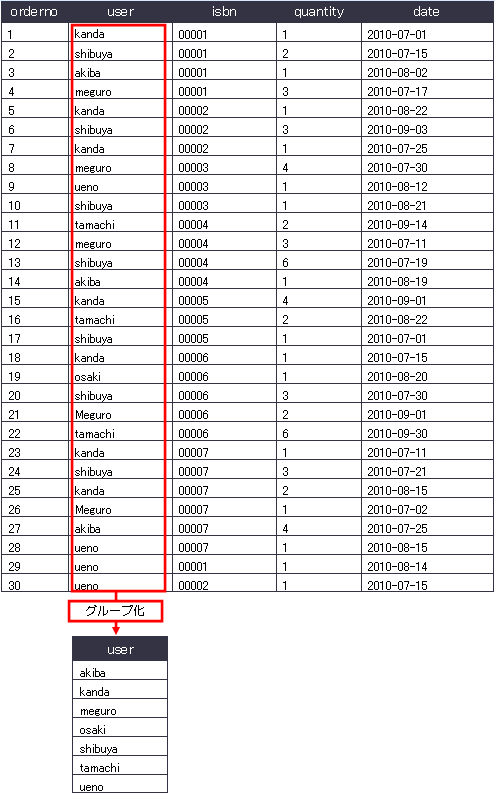
* 新規テーブルへのデータ登録 次に下記のデータを登録してください。
orderno
user
isbn
quantity
date
1
kanda
00001
1
2010-07-01
2
shibuya
00001
2
2010-07-15
3
akiba
00001
1
2010-08-02
4
meguro
00001
3
2010-07-17
5
kanda
00002
1
2010-08-22
6
shibuya
00002
3
2010-09-03
7
kanda
00002
1
2010-07-25
8
meguro
00003
4
2010-07-30
9
ueno
00003
1
2010-08-12
10
shibuya
00003
1
2010-08-21
11
tamachi
00004
2
2010-09-14
12
meguro
00004
3
2010-07-11
13
shibuya
00004
6
2010-07-19
14
akiba
00004
1
2010-08-19
15
kanda
00005
4
2010-09-01
16
tamachi
00005
2
2010-08-22
17
shibuya
00005
1
2010-07-01
18
kanda
00006
1
2010-07-15
19
osaki
00006
1
2010-08-20
20
shibuya
00006
3
2010-07-30
21
meguro
00006
2
2010-09-01
22
tamachi
00006
6
2010-09-30
23
kanda
00007
1
2010-07-11
24
shibuya
00007
3
2010-07-21
25
kanda
00007
2
2010-08-15
26
meguro
00007
1
2010-07-02
27
akiba
00007
4
2010-07-25
28
ueno
00007
1
2010-08-15
29
ueno
00001
1
2010-08-14
30
ueno
00002
1
2010-07-15
INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('kanda','00001',1,'2010-07-01'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('shibuya','00001',2,'2010-07-15'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('akiba','00001',1,'2010-08-02'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('meguro','00001',3,'2010-07-17'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('kanda','00002',1,'2010-08-22'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('shibuya','00002',3,'2010-09-03'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('kanda','00002',1,'2010-07-25'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('meguro','00003',4,'2010-07-30'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('ueno','00003',1,'2010-08-12'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('shibuya','00003',1,'2010-08-21'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('tamachi','00004',2,'2010-09-14'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('meguro','00004',3,'2010-07-11'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('shibuya','00004',6,'2010-07-19'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('akiba','00004',1,'2010-08-19'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('kanda','00005',4,'2010-09-01'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('tamachi','00005',2,'2010-08-22'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('shibuya','00005',1,'2010-07-01'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('kanda','00006',1,'2010-07-15'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('osaki','00006',1,'2010-08-20'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('shibuya','00006',3,'2010-07-30'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('meguro','00006',2,'2010-09-01'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('tamachi','00006',6,'2010-09-30'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('kanda','00007',1,'2010-07-11'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('shibuya','00007',3,'2010-07-21'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('kanda','00007',2,'2010-08-15'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('meguro','00007',1,'2010-07-02'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('akiba','00007',4,'2010-07-25'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('ueno','00007',1,'2010-08-15'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('ueno','00001',1,'2010-08-14'); INSERT INTO orderinfo(user,isbn,quantity,date) VALUES('ueno','00002',1,'2010-07-15');